728x90
import pandas as pd
# 데이터 불러오기
population_number = pd.read_csv('population_number.csv',
index_col = '도시', encoding = 'euc-kr')
# euc-kr은 한글을 읽도록 설정하는것
population_number
# 데이터프레임 인덱싱
# 1) loc 사용 : 인덱스명, 컬럼명 사용
print(population_number.loc['서울', '2015'])
# 2) iloc 사용 : 인덱스 넘버 사용
print(population_number.iloc[0,1])
type(population_number.iloc[0,1])
# 데이터 프레임 슬라이싱
# 1) loc 사용 : a <= x <= b 인 x 출력
print(population_number.loc['서울':'부산', '2015':'2010'])
print('')
# 2) iloc 사용 : a <= x < b 인 x 출력
print(population_number.iloc[0:2, 1:3])
type(population_number.iloc[0:2, 1:3])
# 컬럼의 데이터 빈도수 세기
population_number['2015'].value_counts()
# 컬럼의 데이터 오름차순 정렬
population_number['2010'].sort_values()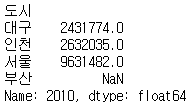
# 컬럼의 데이터 내림차순 정렬
population_number['2010'].sort_values(ascending = False)
728x90
'PROGRAMMING > PYTHON' 카테고리의 다른 글
| [Python] Pandas 다루기 - 카테고리 데이터 (0) | 2021.04.26 |
|---|---|
| [Python] Pandas 다루기 - 점수 데이터 (0) | 2021.04.26 |
| [Python] Pandas (0) | 2021.04.26 |
| [Python] Numpy (0) | 2021.04.26 |
| [Python] 모듈, 패키지, 예외처리, 내장함수 (0) | 2021.04.26 |




댓글