728x90
- Numpy
- 빠르고 효율적인 벡터 산술연산을 제공하는 다차원배열(array) 제공
- 반복문 없이 전체 데이터 배열 연산이 가능한 표준 수학 함수
- 선형대수, 난수 생성, 푸리에 변환
# 모듈 사용하기
import numpy as np
# numpy 모듈을 import하고 앞으로 np라는 이름으로 부른다
- 배열 생성
# 1) 1차원
list = [1, 2, 3, 4, 5]
arr = np.array(list)
print(arr)
arr = np.array([1, 2, 3, 4, 5])
print(arr)
print('')
# 2) 2차원
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2)
z1 = np.zeros([4]) # 0 으로 채운 배열 만들기
o2 = np.ones([3,4]) # 1 로 채운 배열 만들기
r2 = np.random.randn(2,3) # 랜덤한 숫자 배열 만들기
z1, o2, r2
- 배열의 크기 확인하기 : 행과 열 출력
print(arr.shape)
print(arr2.shape)
- 배열의 전체 요소 개수 확인
print(arr.size)
print(arr2.size)
- 배열의 타입
# 배열의 타입 확인
print(arr.dtype)
print(arr.dtype)
print('')
# 타입 지정하여 배열 생성
arr_type = np.array([1.2, 2.3, 3.4], dtype=np.int64)
print(arr_type)
print(arr_type.dtype)
print('')
# 타입 변경하기
arr_type = arr_type.astype('float64')
print(arr_type)
print(arr_type.dtype)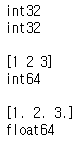
- 배열의 차원 확인
print(arr.ndim)
print(arr2.ndim)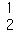
- 배열 연산
arr = np.array([1, 2, 3])
print(arr+arr)
print(arr*arr)
- 브로드캐스팅(Broadcasting) : 모양이 다른 배열들 간의 연산
- 일반적으로 Numpy에서 모양이 다른 배열끼리는 연산 불가
- 특정 조건 만족한다면 다른 배열끼리도 연산 가능
- 차원의 크기가 1일 때 : 두 배열 간의 연산에서 최소한 하나의 배열의 차원이 1이라면 가능
- 차원에 대해 축의 길이가 동일하면 가능

arr = np.array([[1,2,3,4],[10,11,12,13]])
print(arr + arr, '\n')
print(arr + 20, '\n')
print(arr * 100, '\n')
arr1 = np.array([[0,0,0],[10,10,10],[20,20,20],[30,30,30]]) # (4, 3)
arr2 = np.array([[0,1,2],[0,1,2],[0,1,2],[0,1,2]]) # (4, 3)
print(arr1 + arr2, '\n') # (4x3) + (4x3)
print(arr1 + np.array([0,1,2]), '\n') # (4x3) + (1x3)
print(np.array([[0],[10],[20],[30]]) + np.array([0,1,2])) # (4x1) + (1x3)
- 배열 인덱싱
arr = np.array([[1,2,3],[4,5,6]])
print(arr[0])
print(arr[0][0])
print(arr[0,1])
- 배열 슬라이싱
# 1) 1차원 array 슬라이싱
arr1 = np.arange(10)
print(arr1)
print(arr1[3:8])
arr1[3:8] = 99
print(arr1)
# 2) 2차원 array 슬라이싱
arr2 = np.arange(50).reshape(5,10)
print(arr2)
print('')
print(arr2[:2, :])
print('')
print(arr2[:, :2])
print('')
print(arr2[2,1])
- Boolean 색인
name = np.array(['원호', '명호', '병관', '명진'])
bol = np.array([False, True, True, False])
name[bol]
# -> array를 요소마다 매칭하여 True에 해당하는 요소만 출력
name_score = np.array([[60,60],[70,70],[80,80],[90,90]])
print(name=='명호')
print(name_score[name=='명호'])
- Universally function
arr = np.array([[1,2,3,4],[10,11,12,13]])
# 배열 전체의 덧셈, 평균, 곱셈, 최댓값, 최솟값
print(arr.sum(), arr.mean(), arr.prod(), arr.max(), arr.min())
# 배열에서의 최대인 원소의 번호, 최소인 원소의 번호
print(arr.argmax(), arr[1].argmax(), arr.argmin())
| 단일 배열에 사용하는 함수 | |
| 함수 | 설명 |
| abs, fabs | 각 원소의 절대값, 복소수가 아닌 경우에는 fabs로 빠르게 연산 가능 |
| sqrt | 제곱근을 계산, arr**0.5와 동일 |
| square | 제곱을 계산, arr**2와 동일 |
| exp | 지수함수 |
| log, log10, log2, logp | 자연로그, 로그10, 로그2, 로그(1+x) |
| sign | 각 원소의 부호 계산 |
| ceil | 각 원소의 소수자리 올림 |
| floor | 각 원소의 소수자리 버림 |
| rint | 각 원소의 소수자리 반올림, dtype 유지 |
| modf | 원소의 몫과 나머지를 각각 배열로 반환 |
| isnan | 각 원소가 숫자인지 아닌지 NaN 나타내는 불리언 배열 |
| isfinite, isinf | 배열의 각 원소가 유한한지 무한한지 나타내는 불리언 배열 |
| cos, cosh, sin, sinh, tan, tanh | 일반 삼각함수와 쌍곡삼각 함수 |
| logical_not | 각 원소의 논리 부정(not)값 계산, -arr와 동일 |
| 서로 다른 배열 간에 사용하는 함수 | |
| 함수 | 설명 |
| add | 두 배열에서 같은 위치의 원소끼리 덧셈 |
| subtract | 첫 번째 배열 원소 - 두 번째 배열 원소 |
| multiply | 배열의 원소끼리 곱셈 |
| divide | 첫 번째 배열의 원소에서 두 번째 배열의 원소를 나눗셈 |
| power | 첫 번째 배열의 원소에서 두 번째 배열의 원소만큼 제곱 |
| maximum, fmax | 두 원소 중 큰 값을 반환, fmax는 NaN 무시 |
| minimum, fmin | 두 원소 중 작은 값을 반환, fmin은 NaN 무시 |
| mod | 첫 번째 배열의 원소에 두 번째 배열의 원소를 나눈 나머지 |
| greater, greater_equal, less, less_equal, equal, not_equal | 두 원소 간의 >, >=, <, <=, ==, != 비교연산 결과를 불리언 배열로 반환 |
| logical_and, logical_or, logical_xor | 각각 두 원소 간의 논리연산, &, |, ^ 결과를 반환 |
- 영화평점 데이터 분석
import numpy as np
# 데이터 불러오기
data = np.loadtxt('ratings.dat', delimiter = '::', dtype = 'int64')
# delimiter는 txt파일의 구분자를 표시
data
# 데이터 분석하기
print(data.shape)
print(data.size)
print(data.ndim)
# 전체 평점 평균 구하기
data_all_mean = data[:, 2].mean()
data_all_mean
# 각 사용자별 평점 평균 구하기
user_id = np.unique(data[:, 0])
# unique는 중복값을 제거
user_rating = []
for user in user_id :
data_user_mean = data[data[:, 0] == user, 2].mean()
user_rating.append([user, data_user_mean])
user_rating

# 각 사용자별 평균 평점이 4점 이상인 사용자 구하기
four_user_mean = []
for user in user_id :
data_user_mean = data[data[:, 0] == user, 2].mean()
if data_user_mean >= 4 :
four_user_mean.append(user)
np.array(four_user_mean)
728x90
'PROGRAMMING > PYTHON' 카테고리의 다른 글
| [Python] Pandas 다루기 - 인구 데이터 (0) | 2021.04.26 |
|---|---|
| [Python] Pandas (0) | 2021.04.26 |
| [Python] 모듈, 패키지, 예외처리, 내장함수 (0) | 2021.04.26 |
| [Python] 클래스 (0) | 2021.04.26 |
| [Python] 파일 (0) | 2021.04.26 |




댓글