728x90
- dplyr : 데이터 전처리에 가장 많이 사용되는 패키지
install.packages('dplyr')
library(dplyr)
# 데이터 가져오기
exam <- read.csv('csv_exam.csv')
exam
- rename() : 변수명 변경
exam <- rename(exam, korean=science)
# 또는 exam %>% rename(korean=science)
exam
- 파이프 연산자 (%>%) : Ctrl + Shift + m
- 왼쪽에서 오른쪽, 위에서 아래로 읽음
- 여러 개의 함수를 작업 순서에 따라 연속하여 호출 가능
- filter() : 행 추출
# 1반 데이터만 출력하기
exam %>% filter(class==1)
- select() : 열 추출
# id, class, math만 출력하기
exam %>% select(id, class, math)
- arrange() : 정렬
# math 기준 오름차순
exam %>% arrange(math)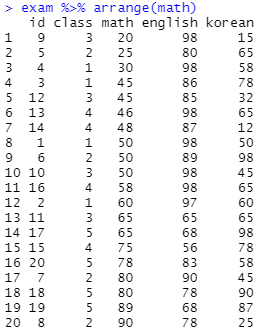
# englist 기준 내림차순
exam %>% arrange(desc(english))
- mutate() : 변수 추가
# 3과목 평균을 정수형으로 추가
exam %>% mutate(mean=as.integer((math+english+korean)/3))
- summarise() : 통계치 산출
exam %>% summary()
- group_by() : 집단별로 나누기
# 각 반별 수학점수 평균 구하기
exam %>%
group_by(class) %>%
summarise(mean_math = mean(math))
# mutate 기존 데이터를 살리고 원본에 새로운 속성 추가
# summarise는 아예 새로운 표를 생성
- left_join() : 데이터 합치기(열)
add <- data.frame(id = 1:20,
mean = c(66, 72, 69, 62, 56, 79, 71, 64, 44, 64, 65, 54, 69, 49, 69, 73, 77, 82, 81, 73))
left_join(exam, add, by='id')
- bind_rows() : 데이터 합치기(행)
add <- data.frame(id = c(21, 22),
class = c(6, 6),
math = c(91, 68),
english = c(55, 74),
korean = c(77, 43))
bind_rows(exam, add)
# by기준이 없어도 합쳐짐
# 단, 두 데이터의 변수명이 같아야 함
728x90
'PROGRAMMING > R' 카테고리의 다른 글
| [R] t검정, 분산분석, 카이제곱 검정 (0) | 2021.07.19 |
|---|---|
| [R] 데이터 전처리 실습 (0) | 2021.07.19 |
| [R] Text Mining과 WordCloud 실습 (0) | 2021.07.19 |
| [R] Text Mining과 WordCloud (0) | 2021.07.17 |
| [R] csv파일 불러오고 살펴보기 (0) | 2021.07.17 |


댓글